Was chi a ponzi ?
Just 18 days ago I asked if chi is a ponzi?. Today we seem to have gotten an answer:
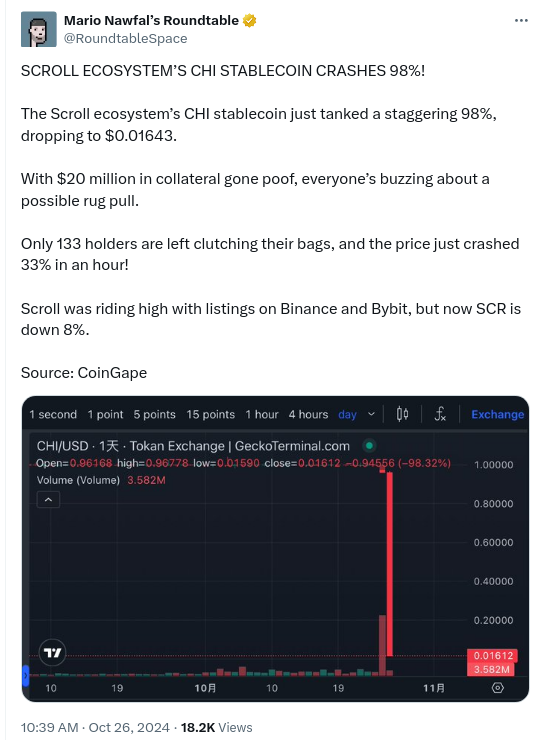
Just 18 days ago I asked if chi is a ponzi?. Today we seem to have gotten an answer:
A while ago on some random place, someone mentioned chi as being a great way to make money. Obviously things that are recommended on random places tend to be great ways to loose money. But somehow it made me curious in what way exactly, so i made a note. And a few weeks later i actually found some time to look around what chi is. I will in this text omit several links as i dont want to drive anyone by mistake to it and also nothing here is investment advice. And also i have no position in chi for the record, obviously.
Chi is a stable coin on the scroll blockchain. It initially was apparently backed by USDC.
This stable coin is mainly tradable on the tokan decentralized exchange. That exchange has a governance token called
TKN and chi has a governance token called ZEN.
Tokan exchange works like many DEXes, people provide liquidity and get payed in the exchanges governance token TKN for that.
Others can then use that liquidity and pay fees to trade. So the value of TKN is key to how much
rewards liquidity providers receive. The biggest LP pair is USDC/CHI with 58M US$ value paying over 66% annualized interest. These numbers of course change every minute.
Now normally these DEXes have rapidly droping interest rates and their governance token drops in value as they use up any funding they have. And then normalize on some low interest rate based on fees that traders pay. But this one here is different, if you lookup TKN, as of today its price goes up exponentially, that shouldnt be.
It comes from chi being minted and used to buy TKN, propping up the price of TKN. This way the TKN price goes up, and the interest rate for liquidity providers stays high as they are paid in TKN. But the careful reader probably already realized the issue here. The minted Chi is not backed by USD and it goes out in circulation, so someone could decide to redeem it for its supposed value of 1US$ per 1CHI. Really funnily someone even setup a dune page to track the CHI being minted and used to buy TKN
So if we simplify this a bit, basically the money backing CHI is used to pay out the high interest rate and this works as long as enough new people join and not too many leave. Do we have a ponzi here ? You decide.
How bad is it ? Well the people behind chi are funnily actually showing that in their analytics page, you just have to explain what each field really is.
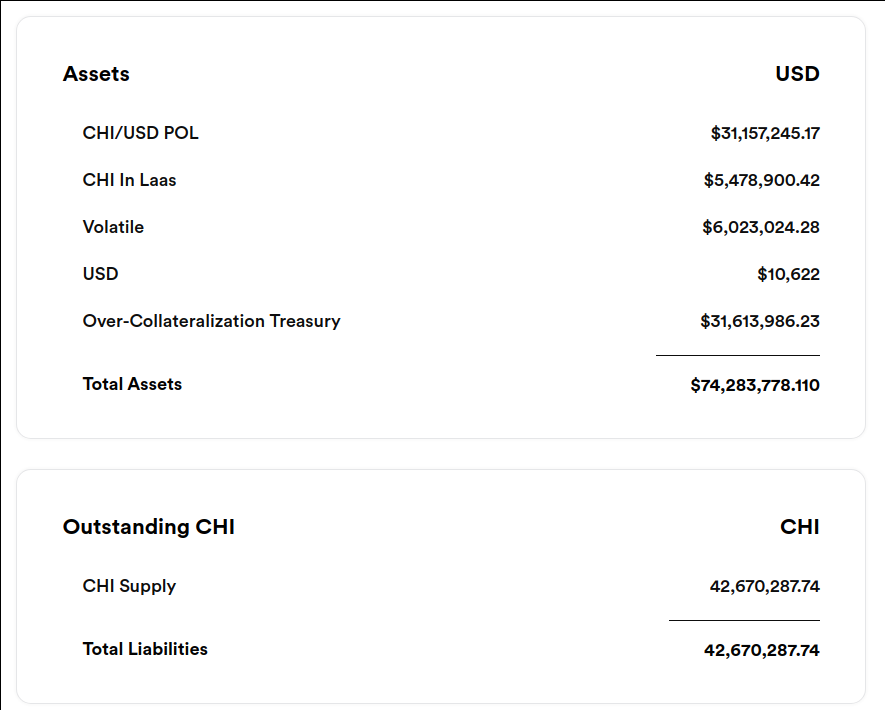
So lets explain what these are, CHI Supply of 42 670 287 is the amount of CHI in existence, some of that are owned by the protocol.
And of today evening compared to morning, theres 4% more, this is rapidly growing.
CHI/USD POL is the USDC+CHI part of the USDC/CHI LP on Tokan that is owned by the protocol. “POL” might be Pool with a typo. This is valid
collateral, the CHI of it can be subtracted from teh CHI Supply and the USDC of it can be used to refund
CHI holders.
CHI In Laas is the CHI part of CHI/ZEN and CHI/TKN LPs on Tokan that is owned by the protocol. This is murky
as a collateral because it only has value if its withdrawn before a bank run happens.
Laas stands for liquidity as a service, in case you wonder.
Volatile and “Over-Collateralization Treasury” are TKN tokens owned by the protocol, they are not usable as collateral, and this is where the real problem starts.
You can look at the “oracle” contract to get these values too and also see from it what each part is.
First, lets pick the best case scenario where we assume the protocol can pull all their assets from the DEX before people try to exit. Also keep in mind that i am using the current values of everything and at another time things will be different.
Here first 31.157M/2(CHI part of the USDC/CHI LP) + 5.478M(CHI of laas) that is 21M of 42.6M are owned by the protocol and we just remove them. Leaving
21.6M CHI owned by users that may want to redeem. The protocol now has the USDC part of their USDC/CHI LP left thats 31.157M/2.
that leaves 6M CHI backed by TKN, while on paper these TKN would have a value of over 37M$. As soon as one starts selling
them, they are going to collapse because basically nothing is backing them, the 2 LAAS positions would be already be
used to reduce the amount that needs to be redeemed. Only about 1M$ remains in eth/tkn that one could use to change tkn into
something of value. So basically In this scenario over 5M$ are missing.
If OTOH the protocol does not pull the LAAS pairs before and they are used by people to trade in their TKN and ZEN into CHI
then the circulating supply of CHI that needs to be redeemed could increase by that amount approaching ~10M $ of missing money.
So ATM basically between a quarter and half of the user owned value behind the chi stable coin seems to not exist anymore.
No, you can have 100 people owning 1 shared US$ and as long as no one takes that 1 US$, everyone can live happy believing they each have 1 US$. Its also possible someone walks up to the box and adds 99$. This is crypto its not impossible someone just pulls 6M$ out of their hat and fixes this hole. But then again, given that the hole becomes bigger every day and the rate by which it grows also grows. I don’t know. I guess ill just hope that all the people are correct, who believe that sticking money into a box will allow everyone to have 66% more each year. Money can be made like that by the central bank or by government bonds or by companies selling a product. But not by wrapping US$ into a funny coin and then providing liquidity between said coin and US$. A coin that seems to have little other use than that.
Ive yesterday updated a 20.04 LTS ubuntu to 22.04. I expected it to just work but do-release-upgrade failed with something like
“The upgrade has aborted. The upgrade needs a total of 6XY M free space on disk ‘/boot’.”
Thats not nice of ubuntu considering the default /boot/ partition size was 500 M when this system was originally setup (i know because i know i left the default).
This system was also setup with disk encryption so simply resizing the partition is not as obvious and simple, not saying it cannot be done, just saying i felt more comfortable with making the update work with 500M /boot than trying to resize it.
So heres a list of solutions. For everyone who runs in this same issue. But before this a few words of caution.
Make a backup or have plan that you LIKE if it goes wrong.
The ubuntu tool is SHIT and this is polite. Its computation of needed space is at best a guess, it simply takes the current kernel size and the current initrd.img sizes and multiplies them by how many are expected to be needed and then asks for free space accordingly. Every number here is wrong. Its not using the actual kernel or initrd sizes, it doesnt use the current compression settings, it doesnt even seem to consider that the currently installed kernels will be removed. In practice for me it overestimated by 156mb but I think it can in corner cases also underestimate the needed space.
/etc/initramfs-tools/initramfs.conf: COMPRESS to lzma (xz is slightly worse)update-initramfs -u, and remember ubuntu (no idea if others will too) will try to change this setting back during the update (it will ask) if you let it, and it changes it back then you may need more space during the update than what the tool computedupdate-initramfs -u set MODULES back to most, run do-release-upgrade update-initramfs -uapt remove and do a apt -f install and apt update && apt dist-upgrade, If you have luck that might fix itI was looking for a way to securely manage my passwords, anything storing my passwords with a 3rd party or all accessible to my computer fail IMHO. Also it had to be practical, something limited to 5 passwords is not. Be convenient, something where one would have to search for a password in a list by hand fails that. And it needed to have a screen so one knew what one approved. A simple one button USB stick does not qualify either as one does ultimately not know what one actually approved. The only device i could find was the mooltipass. So i bought one. It is a cute little thing storing all passwords both securely and also conveniently. And being a nerdy geeky person, i of course had to play with and analyze it. The first thing that sprang out to me was its random number generator
So i looked at its random number generator until i found something. It uses the 2 LSB of each of the 3 axis of an LIS2HH12 accelerometer. This generator was tested with the DIEHARDER battery of tests by its creator before me. I was at first not able to run the DIEHARDER tests because they needed more random data than the device could generate quickly. I tried various tests, simple things like simply trying to compress the data showed no anomalies. The first anomaly i found, i believe was through looking at the frequency spectrum in audacity. To my eye it looked like there was a bias between high and low frequencies. The next step was checking the correlation of various bits. And indeed when one looked at 2 bits and the previous 2 bits from the same channel They where equal 3% more often than they should be. I guess i could have stoped here, but i didn’t :) So i looked at the distribution of matching bits, (3% of these shouldn’t be there and we dont know which of 100 are the 3 bad ones). These 3 could be randomly distributed of course. But by now i had enough data to run some of DIEHARDER and while most tests passed, some of its tests failed for me. I have to say though little things in the command line of DIEHARDER can lead to unexpected results.
I simply counted the number of times each 2bit matches the previous 2bits of the same channel and this occurs about 3% more often than it should. With 1 mb of data: Channel 0 [1.026829 : 1.980986 : 0.992185] Channel 1 [1.031329 : 1.978283 : 0.990388] Channel 2 [1.039171 : 1.974176 : 0.986653] Average [1.032443 : 1.977815 : 0.989742] All 3 [0.968019 1.010415 1.052310 1.111489] /dev/random Channel 0 [1.000765 : 1.998530 : 1.000705] Channel 1 [0.997429 : 2.001644 : 1.000927] Channel 2 [0.997357 : 2.003375 : 0.999268] Average [0.998517 : 2.001183 : 1.000300] All 3 [1.001617 0.999233 0.997958 0.995425 This allows relatively reliably distingishing the mooltipass random numbers from /dev/random with 10kb of data
Looking again at the randomdata. The 3% extra repeats within a channel occur 32 samples apart (that is 24 bytes in the stream or 192 bits). These locations sometimes shift around but preferably occur at indexes 31,63 and 95 of the 96 sample block. When such a run of anomalies breaks from teh same index, the new index tends to be the next in the set {95,63,31}. With these patterns it is possible to reliably distinguish as little as 100-200 bytes from random data. That said, the randomness of this is still plenty for a password and the average human would be way worse generating random data. Care though may need to be applied if this is used for other purposes than passwords. For example DSA signatures are notorious for being sensitive to biases in the used random number generator. I reported the anomalies in the RNG in January of 2023. It was fixed on Apr 18th 2023 with 49359dfc52cdfe743000ac512092085328d5f15b. Software to detect the specific pattern reliably as well as 2 small test samples is availble at randomtests
Heres how this compares to /dev/random dd if=/dev/random of=/dev/stdout count=1 bs=1000 status=none | ./mooltitestwalker mooltiness: 0.89 expected: < 1 in 68% cases, < 2 in 95%, < 3 in 99.7% dd if=/dev/random of=/dev/stdout count=1 bs=10000 status=none | ./mooltitestwalker mooltiness: 0.25 expected: < 1 in 68% cases, < 2 in 95%, < 3 in 99.7% dd if=/dev/random of=/dev/stdout count=1 bs=100000 status=none | ./mooltitestwalker mooltiness: 0.04 expected: < 1 in 68% cases, < 2 in 95%, < 3 in 99.7% dd if=/dev/random of=/dev/stdout count=1 bs=1000000 status=none | ./mooltitestwalker mooltiness: 2.99 expected: < 1 in 68% cases, < 2 in 95%, < 3 in 99.7% dd if=/dev/random of=/dev/stdout count=1 bs=10000000 status=none | ./mooltitestwalker mooltiness: 0.08 expected: < 1 in 68% cases, < 2 in 95%, < 3 in 99.7% and now the random data from mooltipass dd if=~/mooltirandom.bin-copy of=/dev/stdout count=1 bs=1000 status=none | ./mooltitestwalker mooltiness: 3.16 expected: < 1 in 68% cases, < 2 in 95%, < 3 in 99.7% dd if=~/mooltirandom.bin-copy of=/dev/stdout count=1 bs=10000 status=none | ./mooltitestwalker mooltiness: 4.21 expected: < 1 in 68% cases, < 2 in 95%, < 3 in 99.7% dd if=~/mooltirandom.bin-copy of=/dev/stdout count=1 bs=100000 status=none | ./mooltitestwalker mooltiness: 12.91 expected: < 1 in 68% cases, < 2 in 95%, < 3 in 99.7% dd if=~/mooltirandom.bin-copy of=/dev/stdout count=1 bs=1000000 status=none | ./mooltitestwalker mooltiness: 37.46 expected: < 1 in 68% cases, < 2 in 95%, < 3 in 99.7 dd if=~/mooltirandom.bin-copy5 of=/dev/stdout count=1 bs=10000000 status=none | ./mooltitestwalker mooltiness: 115.95 expected: < 1 in 68% cases, < 2 in 95%, < 3 in 99.7% As you can see with just 1000 bytes we are already more than 3 standard deviations away from random data. And after that it very quickly becomes something that a random number generator would not generate in the lifetime of the universe not even if you fill the whole universe with random number generators should you see this sort of statistics once Heres the test results for 100,200,300,400,500 bytes with mooltitestcycler for i in `seq 100 100 500` ; do dd if=~/mooltirandom.bin-copy of=/dev/stdout bs=$i count=1 status=none | ./mooltitestcycler ; done moolticycles: 3.00, this or larger is expected 0.27 % of the time in random data. moolticycles: 4.58, this or larger is expected 0.00046 % of the time in random data. moolticycles: 6.00, this or larger is expected 2E-07 % of the time in random data. moolticycles: 6.93, this or larger is expected 4.3E-10 % of the time in random data. moolticycles: 7.75, this or larger is expected 9.5E-13 % of the time in random data. Same but with another testsample to make sure this is not a one off for i in `seq 100 100 500` ; do dd if=~/mooltirandom2.bin of=/dev/stdout bs=$i count=1 status=none | ./mooltitestcycler ; done moolticycles: 3.00, this or larger is expected 0.27 % of the time in random data. moolticycles: 4.58, this or larger is expected 0.00046 % of the time in random data. moolticycles: 6.00, this or larger is expected 2E-07 % of the time in random data. moolticycles: 6.93, this or larger is expected 4.3E-10 % of the time in random data. moolticycles: 7.75, this or larger is expected 9.5E-13 % of the time in random data. In fact i notice now the results are exactly the same, interresting cmp ~/mooltirandom2.bin ~/mooltirandom.bin-copy /home/michael/mooltirandom2.bin /home/michael/mooltirandom.bin-copy differ: byte 1, line 1 heres the control test with /dev/random for i in `seq 100 100 500` ; do dd if=/dev/random of=/dev/stdout bs=$i count=1 status=none | ./mooltitestcycler ; done moolticycles: 0.00, this or larger is expected 1E+02 % of the time in random data. moolticycles: 0.31, this or larger is expected 76 % of the time in random data. moolticycles: 0.58, this or larger is expected 56 % of the time in random data. moolticycles: 0.44, this or larger is expected 66 % of the time in random data. moolticycles: 0.77, this or larger is expected 44 % of the time in random data. and a bigger sample to show the runs: dd if=~/mooltirandom.bin-copy5 of=/dev/stdout bs=2000000 count=1 status=none | ./mooltitestcycler Run 1731 at phase 31 Run 7496 at phase 95 Run 3323 at phase 63 Run 196 at phase 31 Run 195 at phase 95 Run 3540 at phase 63 Run 2459 at phase 31 Run 777 at phase 95 Run 775 at phase 63 Run 195 at phase 31 Run 583 at phase 95 Run 778 at phase 63 Run 1585 at phase 31 Run 1126 at phase 95 Run 971 at phase 63 Run 5047 at phase 31 Run 7141 at phase 95 Run 1741 at phase 63 Run 4643 at phase 31 Run 197 at phase 95 Run 577 at phase 63 Run 197 at phase 31 Run 2907 at phase 95 Run 4040 at phase 63 Run 1572 at phase 31 Run 196 at phase 95 Run 2903 at phase 63 Run 1355 at phase 31 Run 195 at phase 95 Run 196 at phase 63 Run 584 at phase 31 Run 143 at phase 95 Run 51 at phase 63 Run 195 at phase 31 Run 3099 at phase 95 Run 196 at phase 63 Run 1164 at phase 31 Run 2445 at phase 95 Run 2589 at phase 63 Run 4553 at phase 31 Run 7145 at phase 95 moolticycles: 499.67, this or larger is expected 0 % of the time in random data.
A 2nd issue i found and reported on 7th feb 2023 is that when the device is violently shaken, the accelerometer saturates and clips at 2g, this makes the 2 LSB of the affected channel(s) be 00 or 11 more often than expected in a random stream of data. So please dont use the mooltipass while doing high G maneuvers in a fighter jet or any other activity that subjects it to high g forces. Also with some effort one can shake a 3 axis accelerometer so that all 3 axis clip at the same time. There also may be a delay between the generation and use of random data. Ideally when the full 16bit sample clips it should be discarded and not used. While discarding one kind of sample that was equally frequent, introduces a bias, the clipping cases are not equally frequent. They either do not occur at all in a still environment or occur disproportionally frequent.
Except these, i found no further flaws in the random data. Personally i would recommend to use some sort of hash or other cryptography to mix up the accelerometer bits. Heating or cooling (in my freezer with long USB cable) the device did not introduce measurable bias and also feeding ~60 mega byte stream of data into the PRNG NIST-Statistical-Test-Suite did not show any anomalies after the fix. Of course one can only find flaws in such data streams, never proof the absence of flaws. Also it must be said that i could not find any reference by the manufacturer of the chip to randomness of the LSBs. So while AFAIK many devices use accelerometer data as source of random data, there seems no guarantee that a future revision of that chip doesn't produce less random bits. What i can say, is thus just about the device i looked at and for that, the random data is much better than what a person would generate by "randomly" pressing keys. People are very biased in what characters they use in passwords even when they try to be random. Also passwords are generally too short for this anomaly to allow distinguishing 1 password from another with a unbiased RNG. A password that one believed contained n*192 bits of entropy really only contained n*190 before the fix. All this assumes the device is not violently shaken while used.
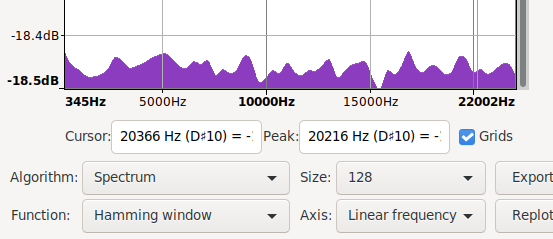
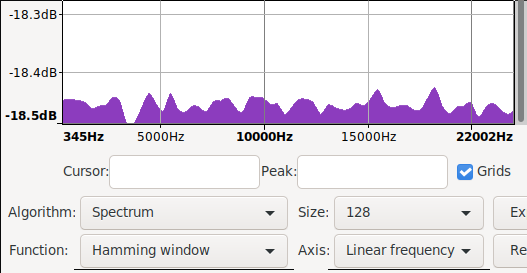
Took me a bit to find and restore the original spectrum i saw. While doing that i also noticed that using signed 8bit results in a spectrum biased the other way. The original ones are unsigned 8bit.
 |
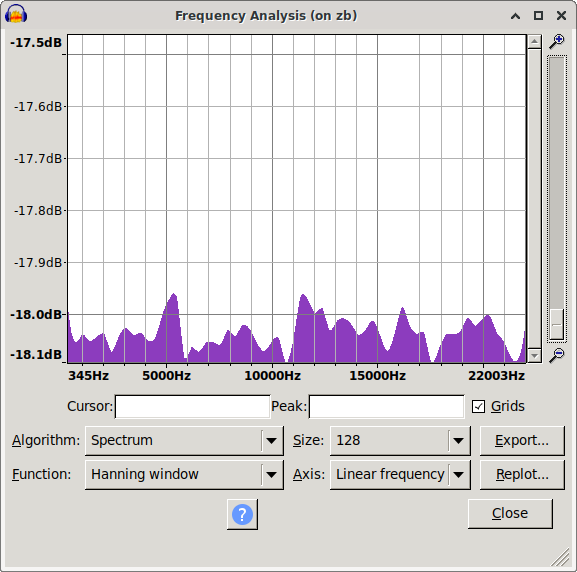
|

|
| mooltipass pre fix spectrum | /dev/random control spectrum | mooltipass post fix spectrum |
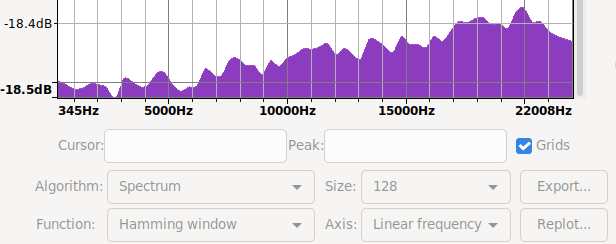 |
 |
 |
| recreated mooltipass pre fix spectrum | /dev/random spectrum | mooltipass post fix spectrum |
Ill write a separate article about dieharder later, the thing is finicky and this is already quite complex
Updated this article multiple times (last on 2023-05-24) to include more details, pictures and minor corrections
Full disclosure, i was offered a reward for finding and reporting the bug.
I was playing around with a VM remotely. Without much thinking i setup a VPN and hit enter after the connect command.
It worked fine, or rather i suspect it did because it blocked the connection to the router through which i accessed it.
Now I could have gotten in the car and driven over to the thing or just ignored it as it had no real use anyway. But it turns out it was too hard for me to just ignore it. That had to be fixable remotely.
I would have expected virtualbox to have some sort of serial console or something like that. And iam sure it has a host of ways to recover this nicer but what i found first and that worked was this:
vboxmanage controlvm (name) screenshotpng this.png ; ffplay this.png vboxmanage controlvm (name) keyboardputstring "foobar" vboxmanage controlvm (name) keyboardputscancode 12 34 56
With these we can look at the screen and we can enter things, thats more than enough to recover it. One thing to keep in mind is that the keyboardputstring commend seems to assume a us keyboard layout.
The 2nd thing to keep in mind if you use this for a similar case, you want to make sure you do not put any passwords into any shell history files. At least not without realizing it and changing the password then
A few days ago i wanted to print a page, nothing special here thats a common thing. But this time was different, my Samsung CLP-365 color laser printer did not print, its main LED red, the 4 toner leds all the same and lighting. On the linux side no error message or anything. Paper was in it, no paper stuck anywhere, power cycling did not help. None of the button combinations i could find that where intended to print debug information did print anything. Searching the wide net lead to a service manual and the tip to look at the display which my printer did not had and some windows software which required a windows machine. A youtube video pointed to the waste toner container but that was not the reason for the failure though it was messy.
What finally helped was connecting the printer to a mac, its printer drivers finally provided a useful error message, namely that the yellow toner cartridge was incompatible. It of course was not a original samsung one because the originals cost as much as a new printer. The other 3 cartridges where still the originals, the yellow one was bought from amazon a bit less than a year ago and it worked fine for a few months. (and this seemed not related to a firmware update)
The final confirmation that this was the issue came today as i received a replacement yellow toner cartridge again non original of course. And putting that in the printer, it came back to life, for now at least.
Iam not sure what i should think about this, but this is uncool. First samsung WTF, why if theres a fatal issue with a toner cartridge why do the LEDs for the toners all light up equally that gives 0 hope to one finding the issue. And iam not commenting about the whole toner original vs compatibility thing except id like the CEOs of all th e printer manufacteurs that make it hard to produce compatible toner cartridges to cleanup all the avoidable waste this creates. Go with a row boat please to the Great Pacific Garbage Patch and pick your incompatible toners and still good but misdiagnosed printers out and recycle them properly.
Thanks
What i write here is going to be outdated in a few days or weeks likely but anyway, some thoughts about this …
Ive been following the information updates in the last few days, less the mainstream news. And normally i do not pay much attention to either the mainstream news nor any non mainstream stuff. But since about the 13th or so ive the feeling from what iam reading that this might turn into a pandemic. I hope iam wrong, this is not my area of expertise at all.
I hope the dumb extrapolation of numbers one can do is wrong because if this virus is anywhere as deadly as currently predicted and if it spreads widely. A worst case scenario could have many dead. Basically if this infects a significant fraction the world population, and the current fraction of seriously ill patients would apply in that scenario. There would not be enough hospitals, ICUs, … . People could be dieing because of the medical system being overwhelmed by the cases of serious illness.
So, i hope iam wrong. I hope this is successfully contained, people are quarantined everywhere and the virus dies instead of people. And from what iam reading it seems china is successful in containing it, but i have difficulty imagining all countries will.
I hope by isolating the most severe cases the virus will evolve to become more benign. A virus which causes severe disease which causes quick detection and isolation doesnt spread well, one that produces minor or no symptoms spreads much better. This can push the virus to evolve toward being milder. Of course that only works if a milder variant still spreads equally well, evolution is survival of the fittest after all, it has nothing do do with the hosts survival.
I hope a working vaccine is quickly found, tested and becomes widely available.
I hope there will be enough antiviral medications for the people who need them.
I hope that if it does spread, the politicans will direct resources toward preparing the medical system of their country and teaching citizens about Hygiene.
In some countries wearing a mask to protect against spreading diseases is even outlawed currently. (like the one i am in for example)
Also its socially not particularly accepted, people here rather cough each other in the face, or if they are more polite cough in their hand and then touch everything and everyone from food to other people with that hand. Yeah thats why the flu and the cold spreads so well and why this one might too.
And i dont even want to think or be reminded of the general gen-tech-phobia. Without that more laboratories and researchers would exist who could now work on finding a vaccine or other treatments or just testing samples from patients if they have the virus. It is AFAIK very simple to do a PCR and gel electrophoresis or realtime PCR which is AFAIK how this is detected currently. There are YouTube channels where you can see hobbyists doing PCR and electrophoresis in a garage, shed or similar. Sure for the virus one needs a negative pressure glove box and some additional saftey but still it puzzles me a bit when i read that various countries cant test or cant test as many samples as they need.
Enough off topic talk, I hope this virus disappears, and everyone gets well and no more people die from it or any other virus.
Update 2020-03-14: You can donate to WHO to fight COVID-19 via covid19responsefund.org
A few days ago i noticed a missing mail from james in my ffmpeg-devel folder. Checking my local logs, checking the servers logs it appeared as if it was sent to me and that i never received it locally. I saw some bounce but mailman doesnt seem to keep track of bounce details. James said it might be a fluke and i put it asside. But shortly later another 2 mails that reached the Archives and others did not reach me. So i opened an issue on gandi.net about this which iam using for my mail. A long while ago i switched to gandi as gmx was just a pain if something did not work …
Until this issue was looked into by gandi, i used a 2nd email address to receive mails from ffmpeg-devel reliably. I also as a precaution changed my password and then later went over most of my email setup to check for any potential bad configuration. In the meantime another mail, one from Andreas failed to reach me over gandi but received me over gmx. So i reported that to gandi with all the headers. On the 24th gandi after a bit of back and forth found the email. It was in a Junk folder that one can see in their webmail but which is inaccessible via POP3. There in fact where almost exactly 1000 mails in the Junk folder.
So i switched from POP3 to IMAP and fetched all, sending them through my own spam filtering i have locally. I have to shockingly say that a substantial number of these “Junk” mails, as in 5-10% where miss-classified and where not junk. Mails from the IETF list, from the debian lists, from ffmpeg, some buisness/finance related mails and many IRC logs, just to list what i remember now off the top of my head. The recovered mails seemed to cover a Timespan since july 2019. I do not know if mails prior to july 2019 “expired” in the Junk folder or if that was when this issue started. From my memory gandi did longer ago reject mails on reception so the sender would always get an error and know. Also it feels as if their spam filters where orders of magnitude more accurate in the past. I was a bit foolish to fail to guess that the well working mail service that gandi had wouldnt be “improved”.
Either way, the things of note are
Everyone on youtube, well all the science channels at least are collaborating on planting trees #teamtrees.
So i donated too because well. I like forests :). And in fact Trees are very important, life as we know it maybe would not exist without trees. Without trees all the carbon now locked up in coal might instead be CO2 in the atmosphere. Also so many lifeforms depend on trees …
Ahh and they are a great way to turn CO2 from the atmosphere into wood, the later does not cause global warming.
Here are some forest related pictures i took in 2019


































I just managed to order 15 euro worth of office stuff on amazon for 1 euro 22 cent. And together with buying my first 30 euro giftcard i should theoretically get a 5 euro coupon. So if that worked that means amazon will pay me 3 euro 78 cent for doing probably 2 separate free deliveries of things to me.
2 Deliveries because mysteriously it was out of stock so the gift card would come separate and first i assume.
Not as cool as that case where amazon recently managed to sell 13k USD equipment for less than 100, i wish i knew about that one in time :(
But still cool.
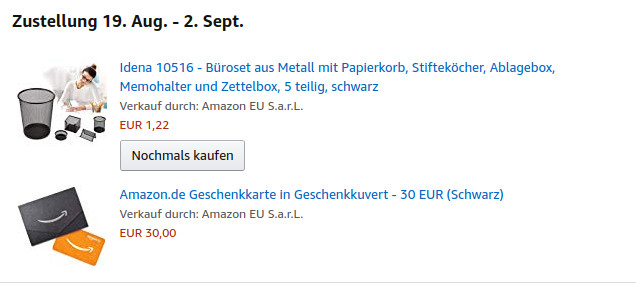
PS: The price already changed back to normal by the time iam writing this
Powered by WordPress
{kind=link}