MDCT
Its really high time to update by blog before it starts rotting. So here are a few words about the modified discrete cosine transform. The reason why iam writing this, is that most docs about the MDCT ive seen are quite obfuscated so i thought maybe i could do better (or worse ;)). Note ive made no attempt to write formal proofs for sake of readability, but they are all very trivial.
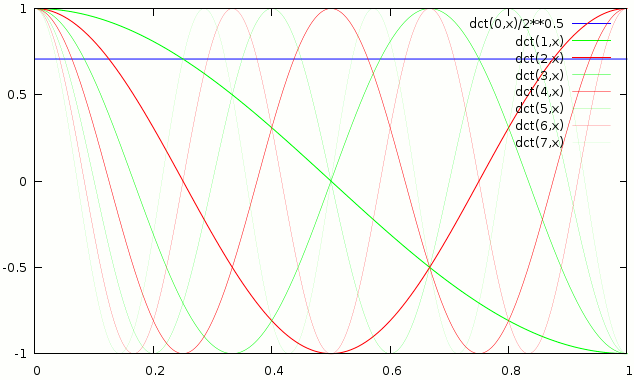
Basis functions of the normal DCT
Basis functions of the MDCT
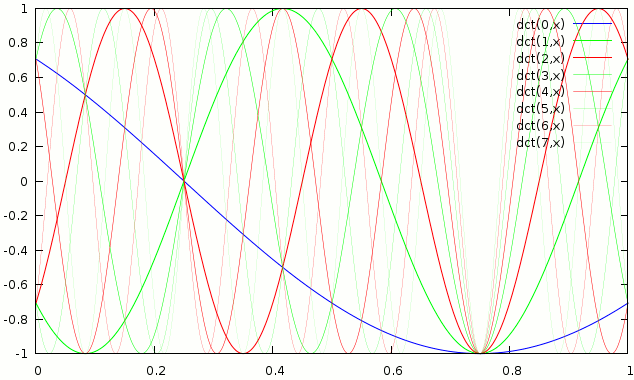
Both of the transforms have orthogonal basis functions, that is the forward transform is simply the series of dot products of the input and the basis functions. While the inverse transform is the sum of the basis functions each scaled by the dot product from the forward transform. This can also be said in a dozen different ways …
What makes the MDCT special, is that it has half as many basis functions as it has inputs. Thus performing the MDCT and then IMDCT on a single block will generally not result in the original. The magic with the MDCT is that it can be overlapped by 50% and then suddenly doing the MDCTs and IMDCTs leads to perfect reconstruction of the original. One can see such lapped transform as a single non lapped transform of infinite length if one wants.
To proof that simply applying the MDCT and then the IMDCT on each block i, which is 50% lapped over block i-1 leads to the original, one really only has to proof that all basis functions are orthogonal (have a mutual dot product = 0). We already assumed that the basis functions of a single MDCT are orthogonal (that can easily be proofen by trigonometric identities if someone is bored). We also know that non adjacent blocks can only have mutually orthogonal basis functions as they do not overlap. Whats left are the adjacent blocks. The proof for their orthogonality is very trivial, if one looks at the graph above, it is immedeatly obvious that there are 2 symmetries one at 0.25 and one at 0.75 in all basis functions. So they behave as (…, c, b, a, -a, -b, -c, …, x, y, z, z, y, x, …). Thus the dot product of 2 basis functions of 2 adjacent blocks is …
… c*x + b*y + a*z – a*z – b*y – c*x … which is obviously 0.
I also should mention that because of these 2 symmetries mentioned above one really just needs to calculate 50% of the IMDCT as the rest is identical up to the sign
The above is still missing one detail, that is that normally the (I)MDCT is used with a window to smoothly get the basis functions down to 0 at their ends. An example with sine window is below
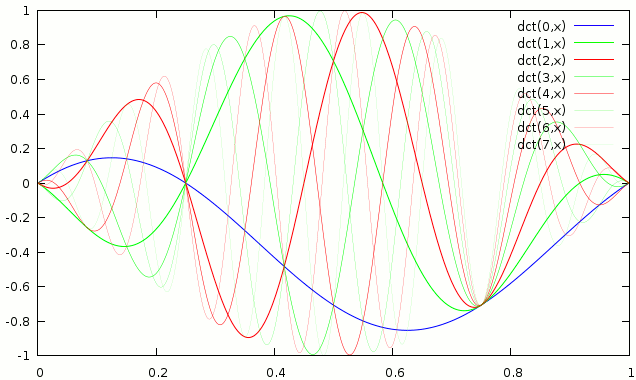
The obvious question is, are the basis functions still orthogonal? The blocks which are not adjacent of course still have to be because their basis functions dont overlap. The basis functions from adjacent blocks assuming a symmetric window
(…c*w-2, b*w-1, a*w0, -a*w1, -b*w2, -c*w3, …, x*w3, y*w2, z*w1, z*w0, y*w-1, x*w-2, …) now have a dot product of …c*w-2*x*w3 + b*w-1*y*w2 + a*w0*z*w1 – a*w1*z*w0 – b*w2*y*w-1 – c*w3*x*w-2 … which is still 0 thus to our “big surprise” any symmetric window maintains orthogonality between 2 adjacent blocks. Whats left are the basis functions within a block. For them the dot product looks like
… c*C*w-22 + b*B*w-12 + a*A*w02 + a*A*w12 + b*B*w22 + c*C*w32 … + x*X*w32 + y*Y*w22 + z*Z*w12 + z*Z*w02 + y*Y*w-12 + x*X*w-22 …
or reordered and common stuff factored out:
… c*C*(w-22+w32) + b*B*(w-12+w22) + a*A*(w02+ w12) +
… x*X*(w32+w-22) + y*Y*(w22+w-12) + z*Z*(w12 + w02)
If we now choose a window for which wi2 + w1-i2 = 2 then the dot product equals what it is without the window, thus our windowed MDCT is still orthogonal and thus easy invertible







