Hardware password managers, accelerometers and random data
I was looking for a way to securely manage my passwords, anything storing my passwords with a 3rd party or all accessible to my computer fail IMHO. Also it had to be practical, something limited to 5 passwords is not. Be convenient, something where one would have to search for a password in a list by hand fails that. And it needed to have a screen so one knew what one approved. A simple one button USB stick does not qualify either as one does ultimately not know what one actually approved. The only device i could find was the mooltipass. So i bought one. It is a cute little thing storing all passwords both securely and also conveniently. And being a nerdy geeky person, i of course had to play with and analyze it. The first thing that sprang out to me was its random number generator
Can we exploit it ?
So i looked at its random number generator until i found something. It uses the 2 LSB of each of the 3 axis of an LIS2HH12 accelerometer. This generator was tested with the DIEHARDER battery of tests by its creator before me. I was at first not able to run the DIEHARDER tests because they needed more random data than the device could generate quickly. I tried various tests, simple things like simply trying to compress the data showed no anomalies. The first anomaly i found, i believe was through looking at the frequency spectrum in audacity. To my eye it looked like there was a bias between high and low frequencies. The next step was checking the correlation of various bits. And indeed when one looked at 2 bits and the previous 2 bits from the same channel They where equal 3% more often than they should be. I guess i could have stoped here, but i didn’t :) So i looked at the distribution of matching bits, (3% of these shouldn’t be there and we dont know which of 100 are the 3 bad ones). These 3 could be randomly distributed of course. But by now i had enough data to run some of DIEHARDER and while most tests passed, some of its tests failed for me. I have to say though little things in the command line of DIEHARDER can lead to unexpected results.
The original findings on the 3% anomaly
I simply counted the number of times each 2bit matches the previous 2bits of the same channel and this occurs about 3% more often than it should. With 1 mb of data: Channel 0 [1.026829 : 1.980986 : 0.992185] Channel 1 [1.031329 : 1.978283 : 0.990388] Channel 2 [1.039171 : 1.974176 : 0.986653] Average [1.032443 : 1.977815 : 0.989742] All 3 [0.968019 1.010415 1.052310 1.111489] /dev/random Channel 0 [1.000765 : 1.998530 : 1.000705] Channel 1 [0.997429 : 2.001644 : 1.000927] Channel 2 [0.997357 : 2.003375 : 0.999268] Average [0.998517 : 2.001183 : 1.000300] All 3 [1.001617 0.999233 0.997958 0.995425 This allows relatively reliably distingishing the mooltipass random numbers from /dev/random with 10kb of data
Periodic anomalies
Looking again at the randomdata. The 3% extra repeats within a channel occur 32 samples apart (that is 24 bytes in the stream or 192 bits). These locations sometimes shift around but preferably occur at indexes 31,63 and 95 of the 96 sample block. When such a run of anomalies breaks from teh same index, the new index tends to be the next in the set {95,63,31}. With these patterns it is possible to reliably distinguish as little as 100-200 bytes from random data. That said, the randomness of this is still plenty for a password and the average human would be way worse generating random data. Care though may need to be applied if this is used for other purposes than passwords. For example DSA signatures are notorious for being sensitive to biases in the used random number generator. I reported the anomalies in the RNG in January of 2023. It was fixed on Apr 18th 2023 with 49359dfc52cdfe743000ac512092085328d5f15b. Software to detect the specific pattern reliably as well as 2 small test samples is availble at randomtests
The original findings on perodic anomalies
Heres how this compares to /dev/random dd if=/dev/random of=/dev/stdout count=1 bs=1000 status=none | ./mooltitestwalker mooltiness: 0.89 expected: < 1 in 68% cases, < 2 in 95%, < 3 in 99.7% dd if=/dev/random of=/dev/stdout count=1 bs=10000 status=none | ./mooltitestwalker mooltiness: 0.25 expected: < 1 in 68% cases, < 2 in 95%, < 3 in 99.7% dd if=/dev/random of=/dev/stdout count=1 bs=100000 status=none | ./mooltitestwalker mooltiness: 0.04 expected: < 1 in 68% cases, < 2 in 95%, < 3 in 99.7% dd if=/dev/random of=/dev/stdout count=1 bs=1000000 status=none | ./mooltitestwalker mooltiness: 2.99 expected: < 1 in 68% cases, < 2 in 95%, < 3 in 99.7% dd if=/dev/random of=/dev/stdout count=1 bs=10000000 status=none | ./mooltitestwalker mooltiness: 0.08 expected: < 1 in 68% cases, < 2 in 95%, < 3 in 99.7% and now the random data from mooltipass dd if=~/mooltirandom.bin-copy of=/dev/stdout count=1 bs=1000 status=none | ./mooltitestwalker mooltiness: 3.16 expected: < 1 in 68% cases, < 2 in 95%, < 3 in 99.7% dd if=~/mooltirandom.bin-copy of=/dev/stdout count=1 bs=10000 status=none | ./mooltitestwalker mooltiness: 4.21 expected: < 1 in 68% cases, < 2 in 95%, < 3 in 99.7% dd if=~/mooltirandom.bin-copy of=/dev/stdout count=1 bs=100000 status=none | ./mooltitestwalker mooltiness: 12.91 expected: < 1 in 68% cases, < 2 in 95%, < 3 in 99.7% dd if=~/mooltirandom.bin-copy of=/dev/stdout count=1 bs=1000000 status=none | ./mooltitestwalker mooltiness: 37.46 expected: < 1 in 68% cases, < 2 in 95%, < 3 in 99.7 dd if=~/mooltirandom.bin-copy5 of=/dev/stdout count=1 bs=10000000 status=none | ./mooltitestwalker mooltiness: 115.95 expected: < 1 in 68% cases, < 2 in 95%, < 3 in 99.7% As you can see with just 1000 bytes we are already more than 3 standard deviations away from random data. And after that it very quickly becomes something that a random number generator would not generate in the lifetime of the universe not even if you fill the whole universe with random number generators should you see this sort of statistics once Heres the test results for 100,200,300,400,500 bytes with mooltitestcycler for i in `seq 100 100 500` ; do dd if=~/mooltirandom.bin-copy of=/dev/stdout bs=$i count=1 status=none | ./mooltitestcycler ; done moolticycles: 3.00, this or larger is expected 0.27 % of the time in random data. moolticycles: 4.58, this or larger is expected 0.00046 % of the time in random data. moolticycles: 6.00, this or larger is expected 2E-07 % of the time in random data. moolticycles: 6.93, this or larger is expected 4.3E-10 % of the time in random data. moolticycles: 7.75, this or larger is expected 9.5E-13 % of the time in random data. Same but with another testsample to make sure this is not a one off for i in `seq 100 100 500` ; do dd if=~/mooltirandom2.bin of=/dev/stdout bs=$i count=1 status=none | ./mooltitestcycler ; done moolticycles: 3.00, this or larger is expected 0.27 % of the time in random data. moolticycles: 4.58, this or larger is expected 0.00046 % of the time in random data. moolticycles: 6.00, this or larger is expected 2E-07 % of the time in random data. moolticycles: 6.93, this or larger is expected 4.3E-10 % of the time in random data. moolticycles: 7.75, this or larger is expected 9.5E-13 % of the time in random data. In fact i notice now the results are exactly the same, interresting cmp ~/mooltirandom2.bin ~/mooltirandom.bin-copy /home/michael/mooltirandom2.bin /home/michael/mooltirandom.bin-copy differ: byte 1, line 1 heres the control test with /dev/random for i in `seq 100 100 500` ; do dd if=/dev/random of=/dev/stdout bs=$i count=1 status=none | ./mooltitestcycler ; done moolticycles: 0.00, this or larger is expected 1E+02 % of the time in random data. moolticycles: 0.31, this or larger is expected 76 % of the time in random data. moolticycles: 0.58, this or larger is expected 56 % of the time in random data. moolticycles: 0.44, this or larger is expected 66 % of the time in random data. moolticycles: 0.77, this or larger is expected 44 % of the time in random data. and a bigger sample to show the runs: dd if=~/mooltirandom.bin-copy5 of=/dev/stdout bs=2000000 count=1 status=none | ./mooltitestcycler Run 1731 at phase 31 Run 7496 at phase 95 Run 3323 at phase 63 Run 196 at phase 31 Run 195 at phase 95 Run 3540 at phase 63 Run 2459 at phase 31 Run 777 at phase 95 Run 775 at phase 63 Run 195 at phase 31 Run 583 at phase 95 Run 778 at phase 63 Run 1585 at phase 31 Run 1126 at phase 95 Run 971 at phase 63 Run 5047 at phase 31 Run 7141 at phase 95 Run 1741 at phase 63 Run 4643 at phase 31 Run 197 at phase 95 Run 577 at phase 63 Run 197 at phase 31 Run 2907 at phase 95 Run 4040 at phase 63 Run 1572 at phase 31 Run 196 at phase 95 Run 2903 at phase 63 Run 1355 at phase 31 Run 195 at phase 95 Run 196 at phase 63 Run 584 at phase 31 Run 143 at phase 95 Run 51 at phase 63 Run 195 at phase 31 Run 3099 at phase 95 Run 196 at phase 63 Run 1164 at phase 31 Run 2445 at phase 95 Run 2589 at phase 63 Run 4553 at phase 31 Run 7145 at phase 95 moolticycles: 499.67, this or larger is expected 0 % of the time in random data.
Shaken not Stirred
A 2nd issue i found and reported on 7th feb 2023 is that when the device is violently shaken, the accelerometer saturates and clips at 2g, this makes the 2 LSB of the affected channel(s) be 00 or 11 more often than expected in a random stream of data. So please dont use the mooltipass while doing high G maneuvers in a fighter jet or any other activity that subjects it to high g forces. Also with some effort one can shake a 3 axis accelerometer so that all 3 axis clip at the same time. There also may be a delay between the generation and use of random data. Ideally when the full 16bit sample clips it should be discarded and not used. While discarding one kind of sample that was equally frequent, introduces a bias, the clipping cases are not equally frequent. They either do not occur at all in a still environment or occur disproportionally frequent.
Random now?
Except these, i found no further flaws in the random data. Personally i would recommend to use some sort of hash or other cryptography to mix up the accelerometer bits. Heating or cooling (in my freezer with long USB cable) the device did not introduce measurable bias and also feeding ~60 mega byte stream of data into the PRNG NIST-Statistical-Test-Suite did not show any anomalies after the fix. Of course one can only find flaws in such data streams, never proof the absence of flaws. Also it must be said that i could not find any reference by the manufacturer of the chip to randomness of the LSBs. So while AFAIK many devices use accelerometer data as source of random data, there seems no guarantee that a future revision of that chip doesn't produce less random bits. What i can say, is thus just about the device i looked at and for that, the random data is much better than what a person would generate by "randomly" pressing keys. People are very biased in what characters they use in passwords even when they try to be random. Also passwords are generally too short for this anomaly to allow distinguishing 1 password from another with a unbiased RNG. A password that one believed contained n*192 bits of entropy really only contained n*190 before the fix. All this assumes the device is not violently shaken while used.
Audacity spectra
Took me a bit to find and restore the original spectrum i saw. While doing that i also noticed that using signed 8bit results in a spectrum biased the other way. The original ones are unsigned 8bit.
 |
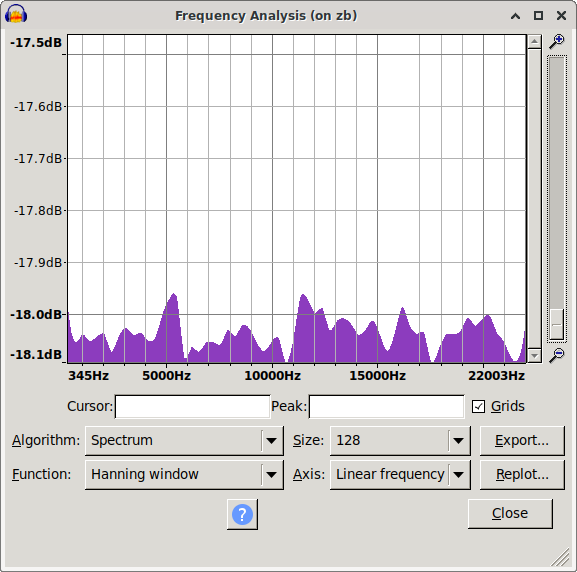
|

|
| mooltipass pre fix spectrum | /dev/random control spectrum | mooltipass post fix spectrum |
Audacity spectra with more data and in signed 8bit ints
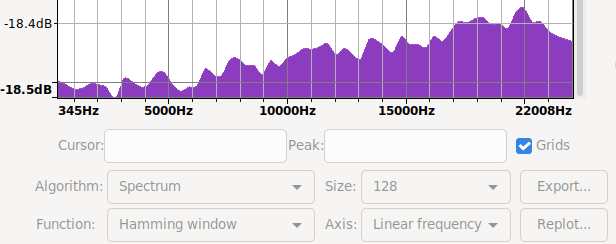 |
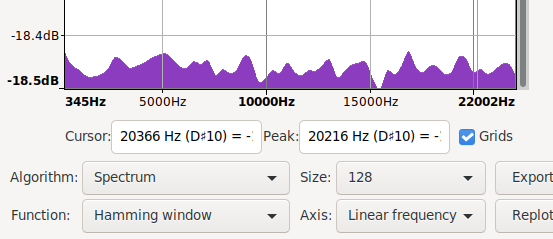 |
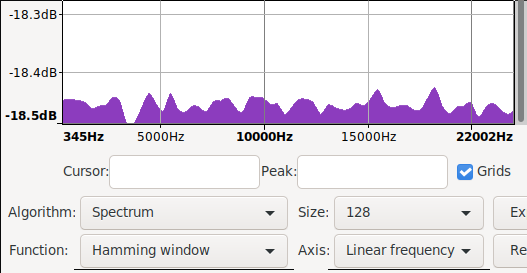 |
| recreated mooltipass pre fix spectrum | /dev/random spectrum | mooltipass post fix spectrum |
Dieharder testsuite
Ill write a separate article about dieharder later, the thing is finicky and this is already quite complex
Updated this article multiple times (last on 2023-05-24) to include more details, pictures and minor corrections
Full disclosure, i was offered a reward for finding and reporting the bug.