Forgotten code, noe and mina
libnoe
libnoe is a library to encode and decode reed solomon codes which i wrote between 2002 and 2006
noe
noe is an application which uses libnoe to generate an error correction file for some data file(s) and use that then to correct a wide varity of possible errors incuding having the data randomly chopped up and reordered. “noe” btw stands for “no error” in case you are wondering, sadly ive never finished the noe application.
The basic idea of how noe would work is that, first the data itself is unchanged, changing it would be inconvenient in many situations. The error correction file is made of many not too large packets, this ensures that any reordering which happens to the error correction file can be corrected by simply searching for the packet headers and looking at some sequence number in the header. The error correction packets now would contain some fingerprints of the data in the datafile(s) that is for example every 100th or 1000th bit of the data file would be stored in some error correction packet in the error correction file. With these fingerprints its possible to detect and correct reorderings which might have happenend to the data file even if just a random subset of the error correction packets are intact. The fingerprints as well as the headers of the error correction packets would contain some small checksums to avoid confusing the code by many wrong values. At last the main content of the error correction packets would simply be interleaved RS codes or more precissely the parity part of them. Btw in case anyone is wondering how data can get randomly choped up and reordered, think of a broken hard disk and fragmented files
Patches to finish noe are of course welcome! :)
mina
mina is the MINimal Alternative which my lazy self did finish. It simlpy takes a file and produces an error correction file which is just a bunch of interleaved RS codes (parity part of them actually) with no header or anything. It also happily eats corrupted files and corrects them
An example of minas correction capability is below, note images have been converted to jpeg to reduce their size and make them vissible in normal browsers. Raw damaged files as tar.gz are available too (mina dz lena.pnm.mina can be used to correct them)
| damaged | recovered |
|---|---|
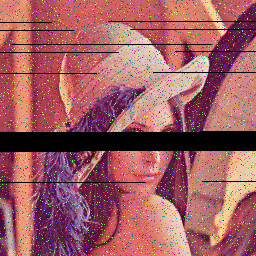 |
 |
 |
 |
Source code under GPL and GIT repositoryis available too, its also quite clean and does compile :). History though is sadly quite incomplete like with the other forgotten code, this time though it was IBMs fault as my private CVS server with the whole history of noe was on a IBM deathstar disk and it seems i had no backup of the RCS files (this is also one of the reasons why i make all that stuff public now, to avoid it being lost due to some other hd failure or stupidity …)
patches are welcome !!! :)