The default wavelet used by the snow codec in ffmpeg is a symmetric biorthogonal compact 9/7 wavelet with rational coefficients with properties very similar to the famous biorthoginal daubechies 9/7 wavelet, it was found by bruteforce search with the goal of having a simple lifting implemenattion and having many vanishing moments or almost vanishing moments, the daubechies wavelet has (4,4) our wavelet has (4,2) vanishing moments
The lifting coefficients are:
| dau97 |
snow |
| -0.443506852 |
-15/32 |
| -0.882911075 |
-4/5 |
| 0.052980118 |
1/16 |
| 1.586134342 |
3/2 |
The resulting wavelet and scaling functions look like:
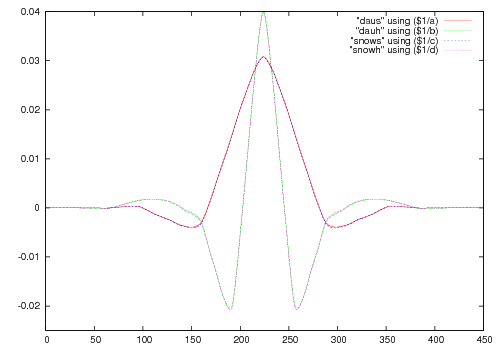
One thing which is still annoying is the 4/5, while this can be approximated pretty well by a multiplication and a shift right but this tends to overflow so something like
x += x+x;
x += x>>4;
x += x>>8;
x >>= 2;
is needed, this one only differs from 4/5 by a factor of ~0.00001, alternatively the 4/5 can be merged into the unquantization step so that
\ | /|\ | /|\ | /|\ | /|\
\|/ | \|/ | \|/ | \|/ |
+ | + | + | + | -15/32
/|\ | /|\ | /|\ | /|\ |
/ | \|/ | \|/ | \|/ | \|/
| + | + | + | + -4/5
\ | /|\ | /|\ | /|\ | /|\
\|/ | \|/ | \|/ | \|/ |
+ | + | + | + | +1/16
/|\ | /|\ | /|\ | /|\ |
/ | \|/ | \|/ | \|/ | \|/
| + | + | + | + +3/2
is changed to
\ | /|\ | /|\ | /|\ | /|\
\|/ | \|/ | \|/ | \|/ |
+ | + | + | + | -3/8
/|\ | /|\ | /|\ | /|\ |
/ | \|/ | \|/ | \|/ | \|/
(| + (| + (| + (| + -1
\ + /|\ + /|\ + /|\ + /|\ +1/4
\|/ | \|/ | \|/ | \|/ |
+ | + | + | + | +1/16
/|\ | /|\ | /|\ | /|\ |
/ | \|/ | \|/ | \|/ | \|/
| + | + | + | + +3/2
Now lets compare quality between the snow and daubechies 9/7 wavelets, this comparission has been done with JasPer with this change and tinypsnr (from ffmpeg) The used test image was the 256×256 lena grayscale image
| Daubechies 9/7 wavelet |
Snows 9/7 wavelet |
| size |
PSNR |
| 618 |
24.02 |
| 1283 |
27.32 |
| 3194 |
31.80 |
| 6503 |
36.82 |
| 13079 |
42.93 |
| 22945 |
47.14 |
|
| size |
PSNR |
| 622 |
24.03 |
| 1295 |
27.33 |
| 3212 |
31.82 |
| 6519 |
36.83 |
| 12981 |
42.87 |
| 22941 |
47.18 |
|








 Original
Original unfiltered
unfiltered pp=hb/vb/dr/fq=8
pp=hb/vb/dr/fq=8 pp=hb/vb/dr/fq=16
pp=hb/vb/dr/fq=16 pp=hb/vb/dr/fq=32
pp=hb/vb/dr/fq=32 spp=6:8
spp=6:8 spp=6:16
spp=6:16 spp=6:32
spp=6:32 uspp=6:8
uspp=6:8 uspp=6:16
uspp=6:16 uspp=6:32
uspp=6:32



